Shrivastava A, Pfister T, Tuzel O, et al. Learning from simulated and unsupervised images through adversarial training[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2107-2116.
该篇论文提出一种Unsupervised方法学习SimGAN model。该model能够使用大量unlabeled real images来增强labeled synthetic images真实性 (Figure 1).
- 显而易见,在real images和synthetic images之间存在一个gap,而实际上,Deep Learning做的事情就是学习两者之间的映射关系。

1. 贡献点
- 使用unlabeled real data来refine synthetic images.
- 结合adversarial loss和self-regularization loss训练Refiner Network (R).
- 使用一些key modification来稳定train以及防止R产生artifacts.
- 分别使用synthetic和refined images训练CNN进行gaze estimation任务,并在MPIIGaze Dataset上测试,进行比较。
2. 训练过程
- SimGAN模型包含Refiner Network(R)和Discriminator Network(D) (Figure 2).

- (Algorithm 1) 对于每个training step,首先训练R $K_g$次,接着训练D $K_d$次。
- 训练网络的过程: Forward Input$\to$Calc Loss$\to$Backward Loss$\to$Optimize Parameters.

3. Loss Function
D包含两部分loss (Formula 2):
- Refined images输入D判别为False的loss(输入与Ground-truth的cross entropy loss)。
- Real images输入D判别为True的loss.

R包含两部分loss (Formula 1,4):
- Refined images输入D判断为True的loss(与D中判别其为False形成对抗Adversarial)
- Synthetic images与refined images之间的L1 loss,乘以权重系数λ(hyper-parameter).
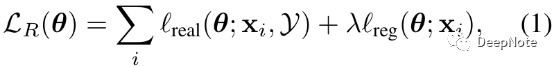
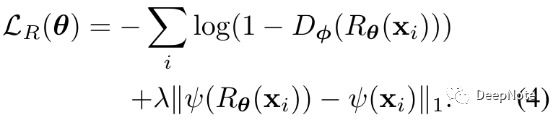
4. Self-regularazition loss
- Preserve the annoation information of the synthetic images.
5. Local Adversarial Loss
- Output a probability map (Figure 3) instead of a vertor.
- Prevent R from over-emphasizing certain image features to fool the current discriminator network, leading to drifting and producing artifacts.

6. History Buffer of Refined Images (Figure 4)
- Prevent D from only focusing on the latest refined images.
- 将refined images输入D之前,首先随机选择一半refined images放入Buffer中,再从Buffer中随机选择同样数目的refined images放回。

- 使用History Buffer的实验结果优于不使用 (Figure 10)

7. Gaze Estimation Task
- 分别使用synthetic images和refined images训练简单的CNN(输出vector(x,y,z)),并在MPIIGaze Dataset上进行测试。
- 从实验结果 (Table 2) 能够看出,经过R增强的refined images的distribution更接近real images的distribution.

8. Details
- R is a ResNet.
- λ=0.001, kd=1, kg=50.
- 1.2M synthetic images, 214K real images.
- More in here
9. Github
- Tensorflow&Keras:wayaai/SimGAN
- Pytorch:AlexHex7/SimGAN_pytorch